lxml.etree._Element 对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from lxml import etree
string = '<div class="post" id="123"><p class="para">abc<a href="/to-go">link</a></p></div>'
doc = etree.HTML(string)
print([i for i in dir(doc) if not i.startswith('_')])
print(type(doc))
|
lxml.etree._Element 的文档地址在这里 lxml.etree._Element 文档
lxml.html.HtmlElement 对象
1
2
3
4
5
6
7
8
9
| from lxml import html
string = '<div class="post" id="123"><p class="para">abc<a href="/to-go">link</a></p></div>'
doc = html.fromstring(string)
print([i for i in dir(doc) if not i.startswith('_')] )
print(type(doc))
|
lxml.etree._ElementTree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from io import BytesIO
from lxml import etree
string = """<div class="post" id="123"><p class="para">abc<a href="/to-go">link</a></p></div>'"""
bytes_string = bytes(string,'utf-8')
html2 = etree.parse(BytesIO(bytes_string),etree.HTMLParser())
print([i for i in dir(html2) if not i.startswith('_')] )
print(type(html2))
|
遍历所有元素的元素绝对Xpath定位
1
2
3
4
5
6
7
8
9
10
| from lxml import html
import lxml
string = '<div class="post" id="123"><p class="para">abc<a href="/to-go">link</a></p></div>'
doc = html.fromstring(string)
alist = doc.xpath("//a")
for a in alist:
tree = lxml.etree.ElementTree(a)
print(tree.getpath(a))
|
比较结论
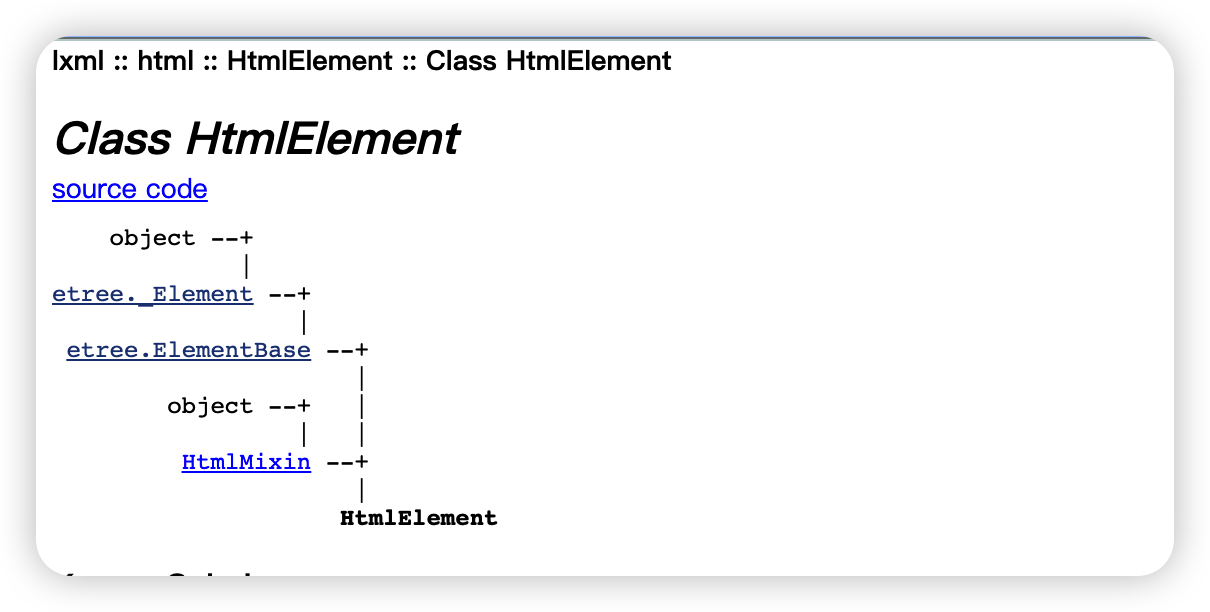
lxml.html.HtmlElement是 lxml.etree._Element 的子类,又继承了HtmlMinin 类,是对lxml.etree._Element 的补充
lxml.etree._Element 和 lxml.html.HtmlElement 的关系在官方文档 地址
其中的继承图如下
简书上有篇文章可以参考讲解的是 lxml.html.HtmlElement 的用法 传送门